

Have you ever heard of hash maps in programming? They’re a super useful data structure that allows you to store and retrieve key-value pairs efficiently. And guess what? Python’s built-in dictionary is implemented using hash maps.
In this article, we will dive into hash maps and explore how they work, how to implement them in Python, and what some common use cases are. We’ll also look at the performance of hash maps compared to other data structures and discuss some advantages and disadvantages of using them.
So whether you’re new to programming or just looking to expand your knowledge, let’s get started.
How Hash Map Works
Alright, let’s dive into how hash maps work.
A hash map is a data structure allowing you to store key-value pairs. The key is used to look up the corresponding value, much like a word in a dictionary.
Behind the scenes, hash maps use something called a hash function. This function takes the key as input and returns a hash code, a unique numeric value representing the key. The hash code is then used to determine where the key-value pair should be stored in the hash map.
When adding a key-value pair to a hash map, the hash code is used to find the appropriate location in the hash map’s underlying array. A hash collision occurs if another key has already been stored at that location. In this case, the hash map uses a collision resolution technique, such as chaining or linear probing, to handle the collision and store the new key-value pair.
When looking up a value in the hash map, the hash code is used to quickly determine where the value should be stored in the underlying array. Then, the hash map checks if the key at that location matches the desired key. If so, the corresponding value is returned. If not, the hash map uses the collision resolution technique to find the correct key-value pair.
Hash maps provide efficient key-value pair storage and retrieval using a hash function to quickly determine where to store and retrieve data in an underlying array.
Implementation of Hash Maps in Python
Let’s take a look at how to implement hash maps in Python. As I mentioned, Python’s built-in dictionary is implemented using hash maps, so we can use dictionaries to work with hash maps in our code.
To create a hash map in Python, we declare a new dictionary using curly braces and add key-value pairs.
Here’s an example:

We can also add key-value pairs to an existing hash map using the same syntax:
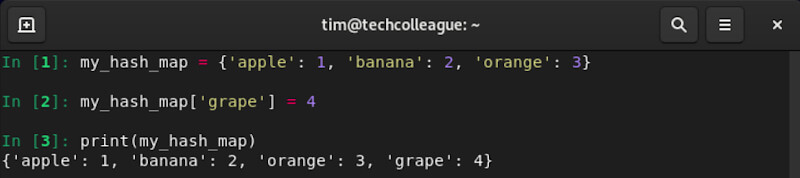
To access the value associated with a key in the hash map, we can use square bracket notation and pass in the desired key:

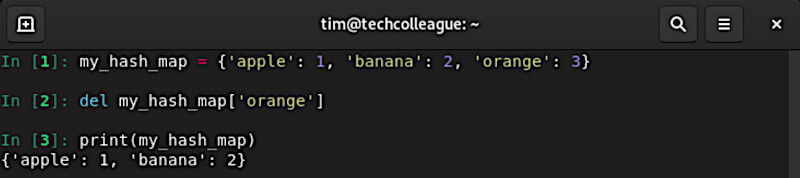
And to remove a key-value pair from the hash map, we can use the del keyword:
That’s all there is to it! Python’s built-in dictionary provides a simple and efficient way to work with hash maps in our code.
Advanced Implementation of Hash Maps in Python
here’s an advanced Python code for implementing hash maps using a custom hash function and handling collisions using separate chaining:
class HashMap:
def __init__(self, capacity=100):
self.capacity = capacity
self.size = 0
self.buckets = [None] * self.capacity
def hash_function(self, key):
# Custom hash function to generate hash codes
hash_code = 0
for char in key:
hash_code += ord(char)
return hash_code % self.capacity
def put(self, key, value):
# Insert a key-value pair into the hash map
index = self.hash_function(key)
if self.buckets[index] is None:
self.buckets[index] = []
for i, (k, v) in enumerate(self.buckets[index]):
if k == key:
self.buckets[index][i] = (key, value)
return
self.buckets[index].append((key, value))
self.size += 1
def get(self, key):
# Get the value associated with a key in the hash map
index = self.hash_function(key)
if self.buckets[index] is None:
return None
for k, v in self.buckets[index]:
if k == key:
return v
return None
def remove(self, key):
# Remove a key-value pair from the hash map
index = self.hash_function(key)
if self.buckets[index] is None:
return
for i, (k, v) in enumerate(self.buckets[index]):
if k == key:
del self.buckets[index][i]
self.size -= 1
return
def __len__(self):
return self.size
def __str__(self):
pairs = []
for bucket in self.buckets:
if bucket is None:
continue
for k, v in bucket:
pairs.append(f"{k}: {v}")
return "{" + ", ".join(pairs) + "}"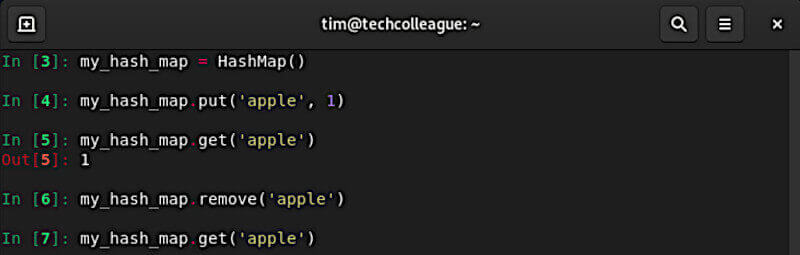
This implementation uses a custom hash function that sums the ASCII values of the characters in the key and returns the result modulo the hash map’s capacity. To handle collisions, it uses separate chaining, where each bucket in the hash map is a list of key-value pairs.
The put() method inserts a key-value pair into the hash map by calculating the index using the hash function, then iterating over the list in the corresponding bucket to see if the key already exists. If it does, the method updates the value for that key; otherwise, it appends a new key-value pair to the bucket.
The get() method retrieves the value associated with a key by first calculating the index using the hash function, then iterating over the list in the corresponding bucket to find the key-value pair with the matching key.
The remove() method removes a key-value pair from the hash map by calculating the index using the hash function, then iterating over the list in the corresponding bucket to find and delete the key-value pair with the matching key.
The __len__() method returns the number of key-value pairs in the hash map, and the __str__() method returns a string representation of the hash map in the format “{key1: value1, key2: value2, …}”.
Related: Python TypeError: not enough arguments for format string
Use Cases of Hash Maps
Now that we know how to implement hash maps in Python let’s explore some use cases for them.
Searching for elements is one of the most basic use cases for hash maps. Since hash maps allow for efficient key-value pair storage and retrieval, they’re a great choice when we need to find an element in a large dataset quickly.
Another use case for hash maps is counting frequencies. For example, if we have a large list of words and want to count how many times each word appears, we can use a hash map to store the word as the key and the count as the value. Then, we can iterate through the list and increment the count for each word as we encounter it.
Hash maps are also helpful for grouping and categorizing data. For instance, if we have a dataset of student grades and we want to group them by letter grade (A, B, C, etc.), we can use a hash map to store the letter grade as the key and a list of students who received that grade as the value.
Finally, hash maps are commonly used in implementing caches. A cache is a way to store frequently used data in a fast-access location, such as memory, to speed up subsequent accesses. Hash maps are an ideal choice for implementing a cache since they provide quick access to data based on a key.
Hash maps are a versatile data structure with many use cases in programming. By providing efficient key-value pair storage and retrieval, they can help us work with large datasets, group and categorize data, and implement caches.
Performance Analysis of Hash Maps
When working with hash maps, it’s important to consider their performance characteristics. While hash maps provide efficient key-value pair storage and retrieval, certain factors can impact performance.
One important factor is the quality of the hash function. If the hash function generates hash codes evenly distributed across the hash map’s underlying array, the hash map will perform well. However, if the hash function generates hash codes that tend to cluster in certain areas of the array, hash collisions will be more likely, and the hash map’s performance will suffer.
Another factor that can impact hash map performance is the load factor. The load factor is the ratio of the number of key-value pairs stored in the hash map to the size of the hash map’s underlying array. As the load factor increases, so does the likelihood of hash collisions, which can reduce the hash map’s performance.
Fortunately, Python’s built-in dictionary automatically resizes its underlying array as the load factor increases, ensuring that hash collisions remain rare and performance remains high.
In general, hash maps provide fast access to data based on a key, with an average case performance of O(1) for insertion, deletion, and lookup.
However, in the worst case, when many hash collisions occur, the performance can degrade to O(n), where n is the number of key-value pairs in the hash map.
When working with hash maps, it’s important to consider factors such as the quality of the hash function and the load factor to ensure optimal performance. Considering these factors, we can use hash maps to store and retrieve key-value pairs in our programs efficiently.
Conclusion
In this article, we’ve explored the basics of hash maps in Python. We’ve learned how hash maps work, how to implement them in Python using dictionaries, and some common use cases for hash maps. We’ve also discussed the performance characteristics of hash maps and how to optimize their performance.
Hash maps are a powerful data structure providing efficient key-value pair storage and retrieval. They can help us work with large datasets, group and categorize data, and implement caches. We can use hash maps to create fast and efficient programs by considering performance considerations.
Python’s built-in dictionary is a great way to work with hash maps in our code. Still, third-party libraries are available that provide additional functionality, such as ordered hash maps and persistent hash maps. By understanding the basics of hash maps, we can choose the right data structure for our specific use case and create more efficient and effective programs.




